测评|如何将WGS分析成本降低30%,效能提升40%
概述
Sentieon® 提供一套生物信息学二级分析工具,以高效率、准确性和一致性为重点处理基因组学数据。与同类开源软件相比,Sentieon Genomics工具在性能方面实现了5到10倍的提升。
MemVerge的Memory MachineTM Cloud 是一个软件平台(简称MMCloud),用于简化云环境中容器化应用的部署。大部分生信分析的共同特征是,CPU 内核和内存访问的资源需求会随着不同执行步骤发生变化。MMCloud 的WaveRider特性通过高效的checkpoint/restore技术,可自动迁移正在运行的容器,而不会丢失执行状态。利用这一特性,可以在不中断运行的前提下,让作业在不同的资源需求阶段,自由切换匹配的机型,永远不会造成资源浪费或不足。
当 Sentieon Genomics 工具与 WaveRider 结合使用时,性能会进一步提高,同时成本也会降低。根据不同配置云主机的按需实例定价模式,当 CPU 和/或内存利用率较高时,通过在短时间内运行较大的虚拟机,可同时优化成本和性能。而当 CPU 和/或内存利用率较低时,使用较小的虚拟机运行,实现成本最优。以全基因组测序(WGS)场景为例,Sentieon Genomics 工具和 Memory Machine TM Cloud的组合方案,可以使运行时间减少 40%、同时实现成本减少 34%。
介绍
对于广大生物信息学家来说,开源工具使测序数据分析技术变得随手可得。近些年,高通量测序技术使得测序效率大幅提升,随之产生的数据增长也越来越快,对测序后的生信分析效率提出了新的要求。Sentieon Genomics 工具对常用的生信流程进行了完全重写,强调计算效率、准确性和一致性,性能比开源软件(常用的如BWA、GATK等)提高了5到10倍。
本文以全基因组测序(WGS)的生信分析为例,以单一配置机型运行Sentieon全流程作为基线,对比Sention+MMCloud 组合方案的性能和成本。
WGS生信分析流程基准
Sentieon 开发的 WGS 基准测试对应的是全基因组测序的生信分析流程,从加载原始数据(以 .fastq 文件)开始,以 .vcf 文件输出结束。WGS 流程包括五个步骤,如表中所示。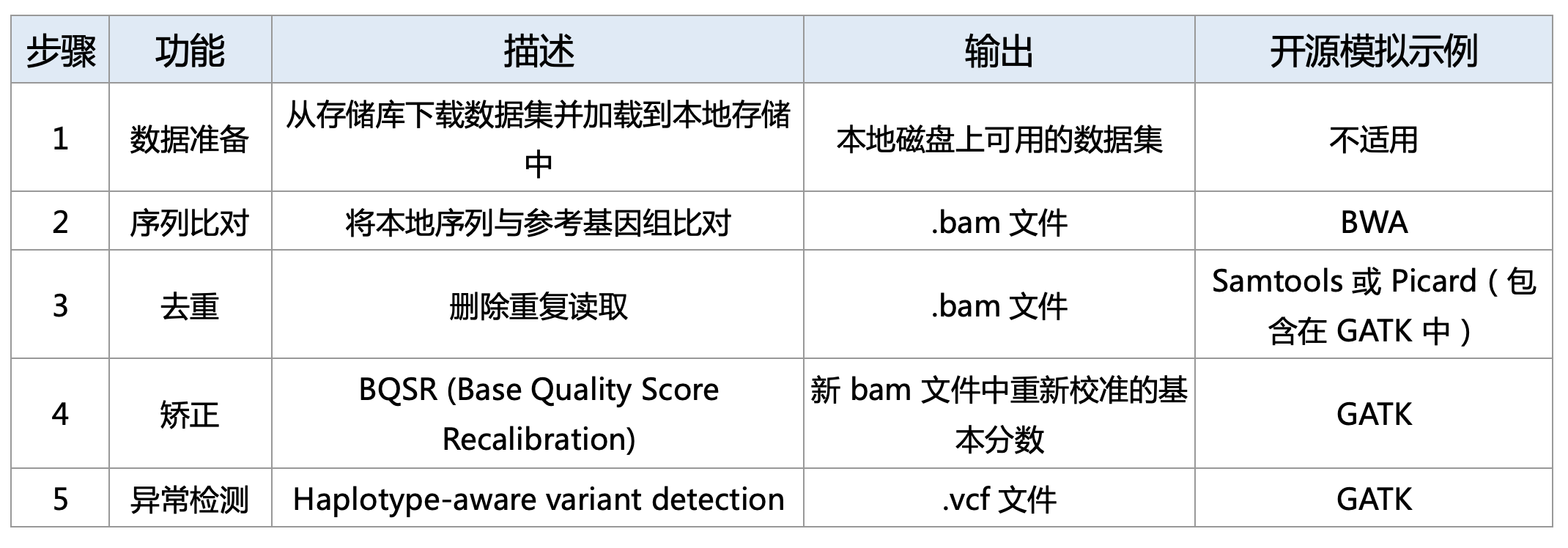
Sentieon Genomics 工具用于单服务器应用程序,即单个脚本在一台机器涵盖多个数据处理步骤,不需要第三方工作流管理应用程序来驱动。
我们将WGS流程分为三个计算阶段阶段(编号步骤请参阅上表)进行性能分析:
- 第 1 阶段:数据准备(步骤1)
- 第 2 阶段:序列映射(步骤 2)
- 第 3 阶段:GATK 流程(去重、矫正、异常检测)(步骤 3 至 5)
测试基线
我们配置了一台按需实例(32 个 vCPU 256 GB 内存),用于运行整个WGS分析流程。
图1 所示的是运行WGS基准测试的CPU和内存使用情况。横轴为时间,纵轴是资源使用情况(CPU使用率和内存使用量)。CPU 使用率显示的是所有 vCPU 的总和,因此最大可能为 3200%。图上的注释显示阶段 1、阶段 2 和阶段 3 相对应的运行时间。表1中有详细的运行时长以及消耗的云资源成本。
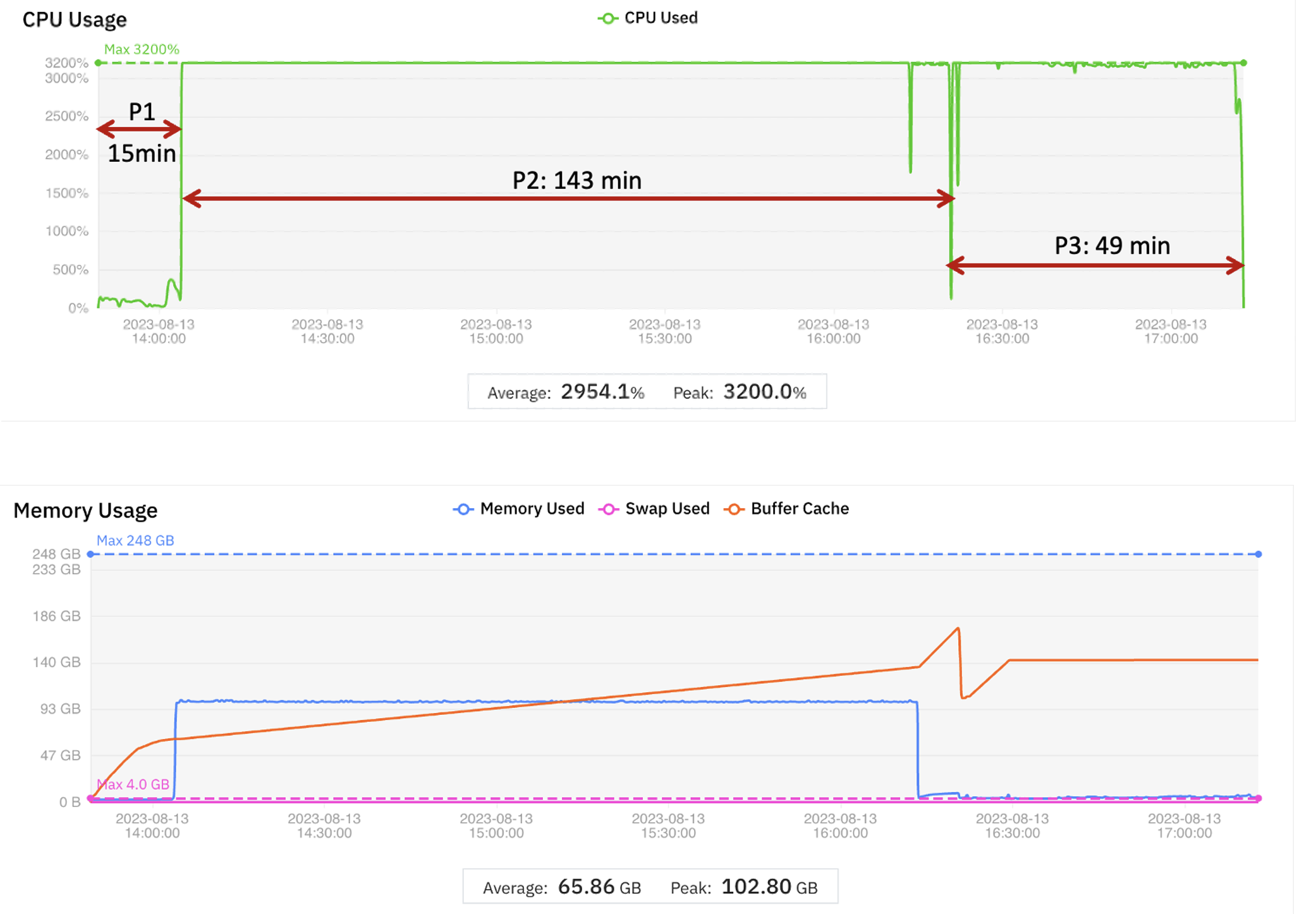
通过分析基线测试的3个不同运行阶段的数据,可观察到以下现象:
- 阶段1仅使用一个 vCPU – 与理论最大值 3200% 相比,CPU 利用率为 100% 或更低。内存利用率也很低。
- 阶段2 通过使用多线程处理充分利用所有 32 个 vCPU。内存利用率远高于阶段1,尽管峰值(103 GB)仍远小于虚拟机实例的 256 GB 容量。
- 阶段3也使用全部 32 个 vCPU,但内存利用率较低(与阶段2相比)
从CPU 和内存使用率可以看出性能和成本优化的点。峰值内存使用率与平均内存的比率很大,这意味着在运行过程中,即使 CPU 利用率很高,内存容量也存在过度配置的情况。但如果虚拟机只根据平均使用量来配置内存,又会将作业运行速度拖慢、甚至因内存不足 (OOM) 错误而失败。
使用 Sentieon+MMCloud 进行 WGS分析
MMCloud 的 WaveRider 特性可将正在运行的作业从一台虚拟机迁移到另一台虚拟机,而不会丢失状态。迁移可以通过手动(使用 CLI 或 Web 界面)、程序控制(将 CLI 命令插入作业脚本)、或基于策略(通过定义CPU或内存利用率的阈值)的方式被触发。迁移正在运行的作业的能力意味着可以在任务不同的执行阶段动态调整底层虚拟机的大小。
为了研究 WaveRider 对 WGS分析指标的影响,我们在一个阶段结束和新阶段开始的交汇处以编程方式触发迁移事件。
方案1:仅优化成本
为了优化成本,在不影响运行时间的前提下,通过MMCloud对不同的运行阶段对云主机进行合理降配。
- 使用小机型(4 个 vCPU 和 32 GB 内存)开始第 1 阶段
- 在第 2 阶段开始时,迁移到大型虚拟机(32 个 vCPU 和 256 GB 内存)
- 在第 3 阶段开始时,迁移到具有相同 vCPU 数量但内存容量较小 (64 GB) 的虚拟机
运行结果如图2显示。运行时间已包含迁移到新虚拟机所需的时间。
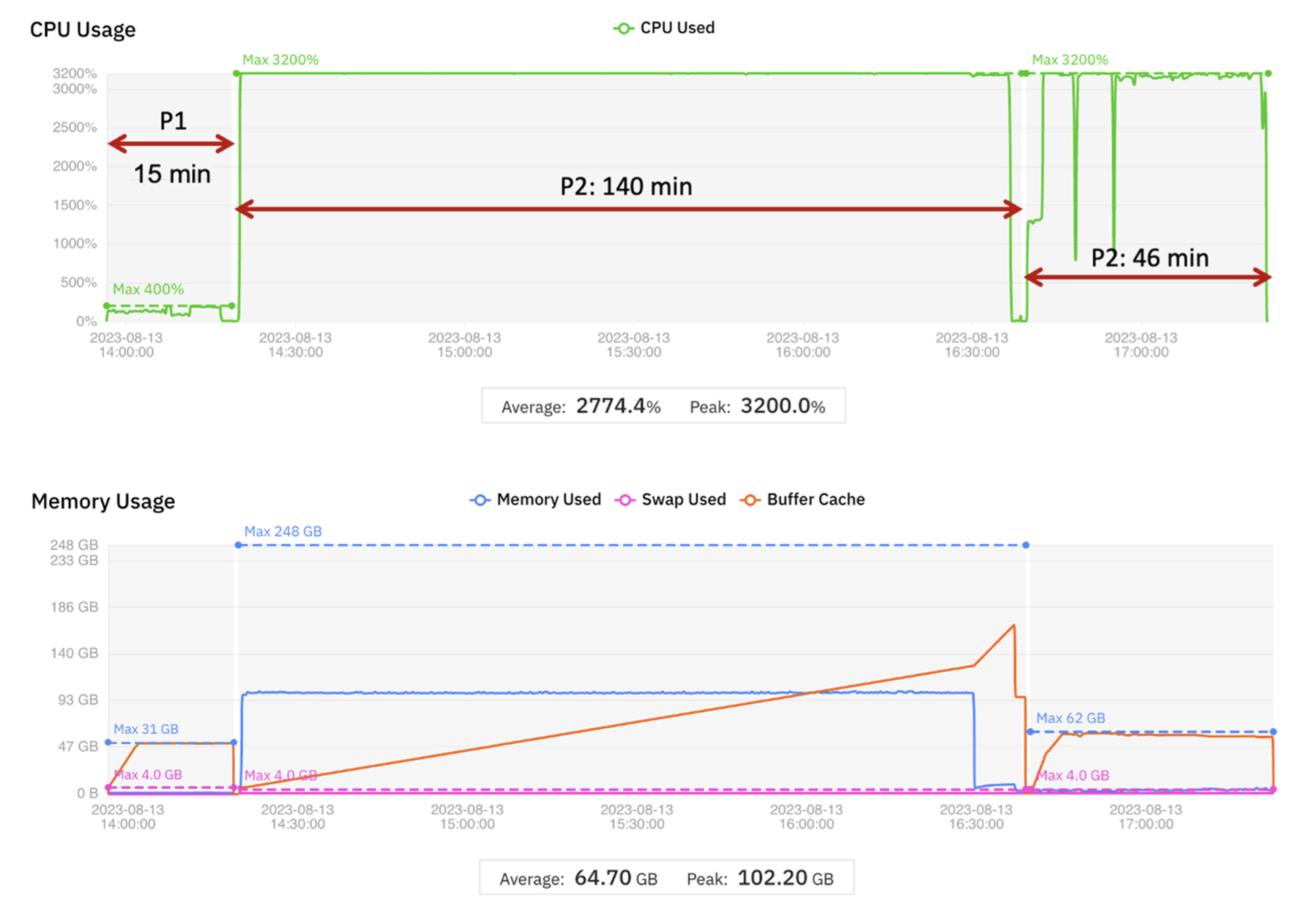
结果显示,使用MMCloud使得云资源成本降低了 16%。各阶段的运行时间在合理抖动范围内,可被视为与基线的各阶段持平。
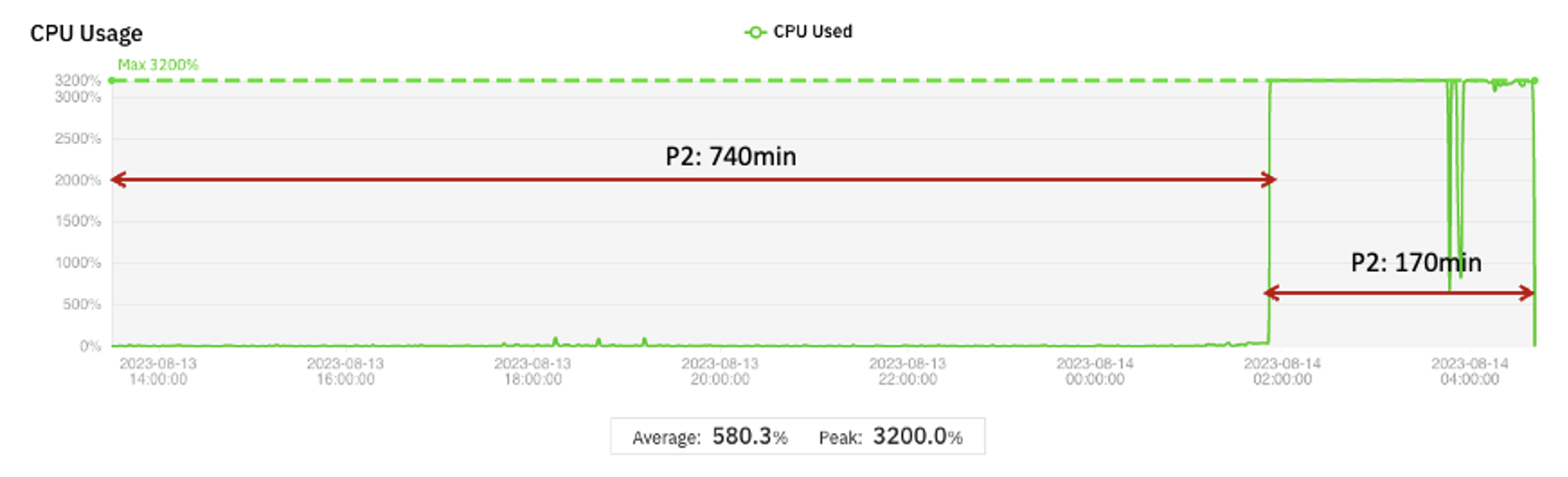
随着数据集大小的增长,完成阶段 1 所需的时间可能会比完成阶段 2 和 3 的时间更长。在这种情况下,如果使用小型虚拟机,则成本节省会增加更多(与基准相比)。图 3 就是这样一个例子。
方案2:成本和性能的综合优化
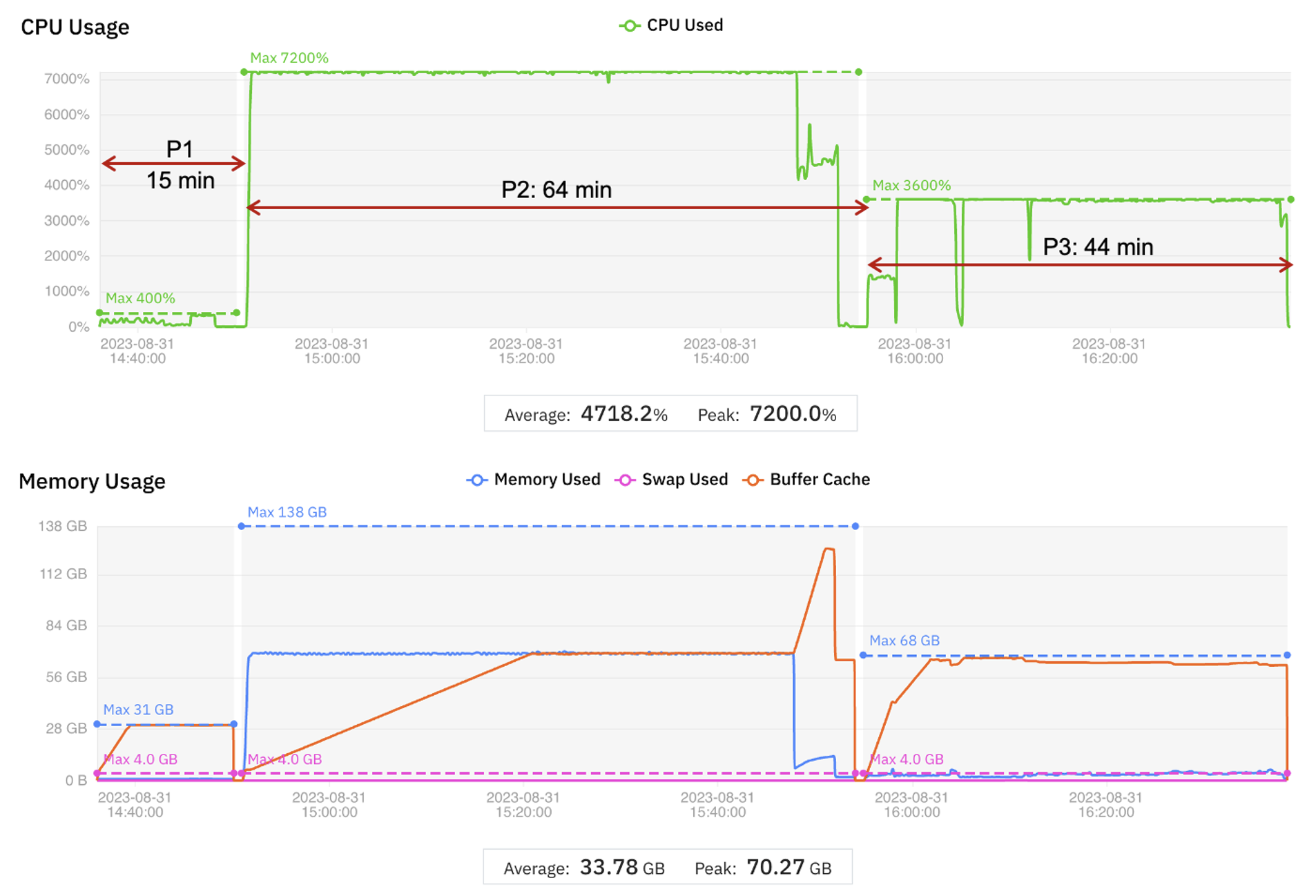
性能优化的关键手段之一是尽量减少计算任务因CPU/内存资源不足而排队或阻塞。Sentieon Genomics 工具提供了一个配置选项来指定最大进程线程数。每个线程会占用1个vCPU资源。如果线程数比vCPU数多,则会因频繁的线程切换(多个线程争抢1个vCPU)对性能产生负面影响。在基线测试中使用了32线程确保与计算资源匹配。在本次测试中,MMCloud对阶段2的虚拟机的配置做了动态升级,vCPU数量从阶段1的4个增加到72个,从而Sentieon的运行线程数也相应地增加到72个,是基线测试的2倍以上。
以下是MMCloud对WGS基准测试做的动态调整:
- 使用小型虚拟机(4 个 vCPU 和 32 GB 内存)开始第 1 阶段
- 在第 2 阶段开始时,迁移到64核以上的大型虚拟机(MMCloud实际选取了72 vCPU 144 GB 内存的机型)
- 将最大线程数增加到与当前vCPU数匹配
- 在第 3 阶段开始时,迁移到具有 至少32vCPU 64GB内存的虚拟机(MMCloud实际选取了36 vCPU 72 GB 内存的机型),将最大线程数减少与新虚机vCPU数匹配。
图4显示了调整后的各阶段的CPU和内存消耗情况,以及运行时长的变化。运行时长已包含迁移到新虚机的时间。表5从成本和运行时长两个维度,与基线数据进行对比。
 这里需要介绍2种向 MMCloud 提交作业时指定虚拟机大小的方法:
这里需要介绍2种向 MMCloud 提交作业时指定虚拟机大小的方法:
- 通过名称指定实例类型
- 指定 vCPU 范围和内存容量范围,例如 vCPU(内存)数量必须至少为 32(128 GB)
对于第2种方法,MMCloud 选择满足 vCPU 和内存要求的价格最低的虚拟机实例。有时可以以较低的价格获得更大的虚拟机,有时则无法获得最低要求的虚拟机。例如,在本次测试中,MMCloud 搜索了至少具有 64 个 vCPU 和 128 GB 的虚拟机,并找到了一个具有 72 个 vCPU 和 144 GB 内存的虚拟机。
借助功能更强大的虚拟机,第 2 阶段的完成时间不到一半,同时仍将第 2 阶段的成本降低了 30%(与基准相比)。最终结果显示,运行完整的WGS基准测试,相比基线运行时长缩短了40.5%,同时云资源成本减少了33.6%,实现了性能和成本的双赢。
结论
Sentieon Genomics 工具缩短了执行各种生信分析流程的运行时长,通过结合 MMCloud 的 WaveRider 功能来调整计算实例的大小,运行时间可以进一步减少 40%。在性能提高的同时,还伴随着显著的成本节省(34%),因为Sentieon软件可以利用额外的vCPU——功能更强大的虚拟机减少运行时长的幅度明显大于额外vCPU在单位时间成本上的增加幅度。同时,成本节省还取决于加载数据与计算所花费的相对时间。数据加载时间越长,MMCloud能带来的成本节省效果越明显。
此外,MMCloud还可以使能 Spot 实例,进一步大幅缩减云资源的开销。